At Open Repositories 2012 the Digital Curation Centre and ICPSR (the Inter-university Consortium for Political and Social Research) organised a workshop to consider issues around the roles and responsibilities of institutional data repositories.
Graham Pryor opened the workshop with an overview of the DCC’s programme of institutional engagements. The workshop featured three presentations relating to projects in the JISC Managing Research Data Programme and other institutional activities (from Cathy Pink on the progress made by the University of Bath’s Research 360 Project; from Sally Rumsey on the work of Oxford’s DaMaRO Project to establish a schema for minimal mandatory metadata; and from Chris Awre on the use of Hull’s institutional repository for curating research data and the History DMP project): on these, more in a forthcoming post. There were also presentations from Ann Green and Jared Lyle of ICPSR on the results of a survey looking at how institutions might work with national data centres (and in what areas institutional repository managers would seek to develop greater expertise through such relationships) and from Gregg Gordon on SSRN, the Social Science Research Network, which has a growing interest in joining up research data assets as well as articles, pre-prints and grey literature.
Angus Whyte has already written a very useful and comprehensive overview of the workshop. I want to focus here on the relationship between emerging institutional research data services and more established national and international data archives. This theme was central to the workshop and was introduced in Graham Pryor’s presentation using the ‘Data Pyramid’ as described in the Royal Society’s Science as an Open Enterprise Report.
The ‘Data Pyramid’ suggests that currently the management and preservation of research data may be considered as happening in four tiers, forming a hierarchy of increased value and permanence.
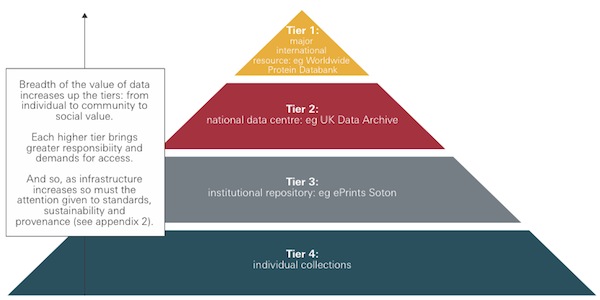
The Data Pyramid – a hierarchy of rising value and permanence, taken from the Royal Society’s Science as an Open Enterprise report, p.60.
Tier One comprises major international resources such as the Worldwide Protein Data Bank. In Tier Two we find the national data centres such as the UK Data Archive and the British Atmospheric Data Centre. Universities’ institutional data repositories and research data services, such as those being piloted in the JISC Managing Research Data programme are found in Tier Three. And in Tier Four come the data collections of individual researchers or research groups: as likely as not these are unsystematically structured and described, reside on temporary storage, shared only with collaborators and not subject to any plan for longer term preservation. Of course, the data pyramid is a useful model, but it does not accurately describe the current state of affairs, largely because Tier Three is underdeveloped (and Tier Four forms a far broader base to the pyramid than any diagram can allow…)
Graham used the data pyramid to ask some searching questions of workshop participants:
- What responsibility should academic institutions have for supporting the data curation needs of their researchers?
- What responsibilities should academic institutions have for curating the data they produce?
- Should academic institutions engage with these questions only where there is no tier 1 or tier 2 service available?
A challenging and provocative way of putting the final question is to ask, as Angus did so neatly in his post, whether universities and other research institutions really want to be ‘lenders of last resort’, providing ‘a home for orphaned data to fill gaps left by national and international disciplinary repositories’?
These are extremely important and pertinent questions and discussions in the workshop were constructive for exploring these issues. Short of proposing precise answers to these questions, what I would like to do here is reconsider the data pyramid and note arguments raised in the Royal Society report as a way of discussing the role, responsibility and purpose of institutional research data services in relation to national and international data archives and collections.
It should be recognised from the start that the curation hierarchy comprising Tiers One-Four should not be considered non-porous and entirely independent. The challenge with which we are faced, in my view, is ensuring that the greatest amount of research data rises up the pyramid to the greatest degree possible and appropriate for the data in question. In particular, this means encouraging potentially valuable and reusable research data to be unlocked from the disaggregated storage and scarcely managed collections that characterises ‘Tier Four’. This objective points to the need for collaboration and coordination between institutional, national and international data services in a number of areas:
- to capture, preserve and then bring together dispersed datasets, adding value through discovery, curation and analysis functions when a critical mass is achieved;
- to promote a research culture that encourages the curation and preservation of research data;
- to help develop and cultivate the skills and services which enable these steps to happen.
In the OR2012 workshop, Ann Green and Jared Lyle made similar points neatly. They recalled Chris Rusbridge’s argument that digital preservation ‘is like a relay race, with different parties taking responsibility for a limited period and then ‘passing the baton”, in order to show how partnerships between institutions and data centres may be helpful to universities seeking to offer services for the long term preservation of selected research data. Ann and Jared also cited the recommendation from a 2007 report that domain specific archives should partner with institutional repositories ‘to provide expertise, tools, guidelines, and best practices to the research communities they serve’. Data centres like the UKDA and BADC are important centres of expertise, with already impressive outreach activities. Nevertheless, anything that can be done to amplify such work and to build up specific partnerships for the propagation of expertise and skills should be encouraged.
Tier Three services in universities have an extremely important role to play in a joined-up research data ecosystem. At present the gulf is cavernous between the relatively small proportion of research data that is preserved in national and international data services (Tier One and Two) and the vast amounts of research data that are of significance and value for verification and reuse, but are effectively lost (in Tier Four).
The Royal Society report recognises this and is unequivocal in its view that institutional research data services (Tier Three) need to be developed and that this is an area of ‘particular concern … in the [curation] hierarchy’ [Science as an Open Enterprise, p.63]. The reason for this is the crucial role of research institutions in propagating the skills, culture and policies which are necessary to respond to the growing imperative to make the most of research data assets. It is by means of institutional policies and services that research data currently lost and inaccessible in the individual collections that form the base of the data pyramid can be made available and reusable.
Much important data, with considerable reuse potential, is also lost, particularly when researchers retire or move institution. This report suggests that institutions should create and implement strategies designed to avoid this loss. Ideally data that has been selected as having potential value, but for which there is no Tier 1 or Tier 2 database available, and which can no longer be maintained by scientists actively using the data, should be curated at institutional (Tier 3) level. [Science as an Open Enterprise, p.63]
Institutional data services can form an elevator by means of which important data collections may emerge from the temporary and inaccessible storage of Tier 4. The Science as an Open Enterprise report makes the point that coherent, more highly curated datasets, to answer very specific research questions, will emerge from the heterogenous collections of services like the Dryad data repository or institutional data repositories.
Data collections often migrate between the tiers particularly when data from a small community of users become of wider significance and move up the hierarchy or are absorbed by other databases. The catch-all life sciences database, Dryad, acts as a repository for data that needs to be accessible as part of journals’ data policies. This has led to large collections in research areas that have no previous repository for data. When a critical mass is reached, groups of researchers sometimes decide to spin out a more highly curated specialised database. [Science as an Open Enterprise, p.62]
The JISC Managing Research Data Programme is helping universities develop policies, strategies and curation services which will allow this role to be performed in the broader data ecology. As already noted on this blog, the Science as an Open Enterprise report recognises the importance of this activity and recommended that it ‘should be expand beyond the pilot 17 institutions within the next five years.’ [Science as an Open Enterprise, p.73] However, if the most is to be made of such investment lessons should be learnt from the approach taken by the Australian National Data Service. Recognising that a significant amount of research data management must happen in institutions – because it is in institutions that the systemic change must happen which will allow the capture of ‘the wide range of data produced by the majority of scientists not working in partnership with a data centre’ – ANDS have also developed an infrastructure, the Australian Research Data Commons, which allows institutional data collections to feed into national and disciplinary collections and discovery portals.

The Australian Data Commons, taken from the Royal Society’s Science as an Open Enterprise report, p.69.
Along similar lines, Gregg Gordon described the value added and connecting services which SSRN could offer as ‘glue for data repositories’. Such services can be built on the data assets curated by Tier 3 institutional data repositories.
To my mind, such arguments and examples make a strong case from a strategic perspective for investment in the development of Tier 3 data services in research institutions and that such data repositories can and should contribute in ways that go beyond being a repository of last resort. But they also recall the need to develop services which allow data to be most easily aggregated and for more highly curated collections to be constructed in response on the one hand to the opportunity created by the development of a critical mass of data in a given area, and on the other hand to the emergence of new research activities ready to exploit this asset.
One reply on “Institutional Data Repositories and the Curation Hierarchy: reflections on the DCC-ICPSR workshop at OR2012 and the Royal Society’s Science as an Open Enterprise report”
[…] have a role to play as a sustainable, trusted repository (see my previous post for arguments around the role of institutional repositories in the curation hierarchy). One can see the attraction for leading departments to develop research and data expertise in […]