What to keep and why; how to support research data management through the lifecyle; and how to make the data citable, discoverable and reusable: these are core questions in research data management. They are questions with both human and technical aspects. These are the issues which Exeter is addressing through advocacy and training, its draft RDM policy and plans for a sustainable service; and which Oxford is seeking to tackle through DataFinder and ‘just enough metadata’.
With a sizeable national investment and an impressive coordinated approach, Australia – in the form of the Australian National Data Service and a host of institutional projects – is providing useful examples of how these questions may be answered.
Natasha Simons, Griffiths University: Enabling data capture, management, aggregation, discovery and reuse
Natasha described the development of the Griffith University Research Hub, a metadata store solution designed as far as possible to automate the collation of new research data held in the university.
Metadata relating to research data created by Griffiths researchers and largely curated in the Griffiths research data repository is exposed by the Research Hub for harvesting to the ANDS Research Data Australia service ‘a set of web pages describing data collections produced by or relevant to Australian researchers. Research Data Australia is designed to promote visibility of research data collections in search discovery engines such as Google and Yahoo, to encourage their re-use.’

Metadata is exposed using RIF-CS (Repository Interchange Format – Collections and Services) a high level schema structured around four classes of objects: collections, parties, activities and services.
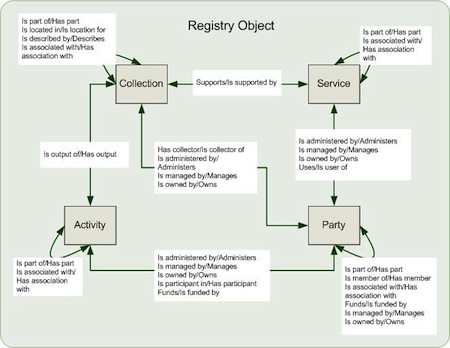
For more on RIF-CS see the ANDS pages about RIF-CS, in particular Learn about RIF-CS.
The Griffiths Research Hub metadata store is based on VIVO, a triple-store solution, and uses the ANDS-VITRO ontology for describing research activity. VIVO-VITRO is one of a number of metadata store solutions encouraged by ANDS and being implemented by ANDS funded projects. For more detail about the Griffiths implementation of VITRO see the DLib article Wolski et al 2011, Building an Institutional Discovery Layer for Virtual Research Collections.
As well as contributing to ANDS’s broader objectives in Research Data Australia, the benefits of the Griffiths Research Hub are to provide a platform of linked information about the university’s research activities – potentially a rich and valuable resource for the management of research information, grant funded projects and the development of collaborations and new initiatives.
Just as the Griffiths Research Hub exposes information about researchers, projects and research data, so Research Data Australia provides a platform to discover information about research data created by Australian researchers. It remains early days – analytics do not yet exist to show to what extent this platform is assisting discovery and reuse – but the potential is clear.
Anthony Beitz, Monash University, Institutional infrastructure for research data management
Anthony described an integrated and strategic approach to supporting researchers eResearch and data management needs. Fundamental to the Monash approach is the recognition that researchers, for good reason, tend to prefer more bespoke, community developed solutions to blunt and generic platforms that are often the wares of centralised IT services. Anthony was unequivocal: ‘If a research community already has an RDM solution, or an emerging one, then it is this which should be adopted and supported.’
One suspects that few would disagree with this in principle… But at a time when in the UK IT support is being withdrawn from research departments, the cry from IT directors will be: ‘Great, but how is this to be resourced.’ A good and pertinent question. But equally, real attention needs to be paid to researchers needs. There is little point in providing generic solutions if these do not respond sufficiently to researchers requirements and are scarcely fit for purpose.
I took Anthony’s point to be that it is of fundamental importance to be sensitive to the objectives and requirements of specific research areas.
For a RDM platform to be effective and have high utility, it must fit in with researchers’ tools, workflows, instrumentation, methodologies, environment, and most importantly culture. As most of these features vary from discipline to discipline, it is unrealistic to believe that a singular approach to RDM will consistently meet researchers’ needs. Indeed, research institutions should expect that a range of RDM platforms will be required in order to accommodate their researchers.
Monash uses a team of developers and agile software development methodology to support this. And the onus is upon engaging with specific research groups and communities. The Monash approach is to work along a decision tree: if possible adopt a third party product; if necessary adapt a product to disciplinary or local needs; and if these options fail to develop the product locally.
The focus on the requirements of reach communities applies both to the support of research activity (data capture, analysis etc; the active data phase) and the curation and archiving of data which in some sense is complete (the data publication phase). For the archiving and publication phase, the Monash approach is manage locally, and promote discovery (inter-)nationally by propagating metadata to national registries such as Research Data Australia, or such disciplinary hubs as may exist. Once again, this seems to push a great deal of responsibility for curation and archiving the way of the institution. The Monash response is to meet this challenge and ‘form a separate specialised support group for RDM infrastructure’.
A lot of institutions will find this approach daunting. But many of the arguments about utility and the need for products that are fit for purpose are fundamentally persuasive. It will be important to understand more about and to learn from the Monash model.
Both these presentations are available on the OR2012 website and may be viewed through the OR2012 YouTube Channel