It’s been an interesting couple of months on the research data discovery front. As phase 2 of the Jisc UK Research Data Discovery Service project draws to a close and we take stock of progress made and lessons learnt, two announcements – one at the recent Research Data Alliance 8th Plenary, and one from Google – indicate strongly that the discovery paradigm is about to change again.
New discovery paradigms
As a metadata developer engaged with a discovery project, it was gratifying to attend a Research Data Alliance interest group on new paradigms for data discovery at the recent plenary in Denver. It was a chance to look at some of the work being done around the world on research data discovery portals and reflect on the next steps to develop these services. I’ve covered part of the discussion in the recent RDA blog post but wanted to revisit a few of the 23 (PowerPoint presentation slide 10) possible directions of travel collected in the session.
- Metadata standards to enhance data discovery, e.g. schema.org and such.
- Identify core elements of Findability.
- Upper-level ontologies for search.
- Implementing schema.org as it exists. How does it apply to science?
The impression I got from the list was a need to focus on discovery. My own experience tells me that it is easy to get bogged down in the variety and richness of the metadata that is available to collect in a discovery service but that sometimes, it’s better to let the repository be the repository and the portal be the portal (a thought echoed by several of the Discovery service pilots at a recent workshop). Concentrating on identifying the key metadata for discovery and pointing to a landing page felt like a welcome adoption of economy and simplicity.
Google and schema.org
It was incredibly prescient then for Google to announce a metadata schema for the discovery of science datasets on the web, using the fundamentals of its structured markup vocabulary that enables search engines to “understand” this metadata. Google identifies seven main groups, all with various (and expandable) properties.
There is a lot more detail on the main development page but a lot of the fields specified are common to the Discovery service profile. Below is a comparison.
| Metadata | Properties | Schema.org* type | UKRDDS** mapping |
| Basic | name | text | Title |
| description | text | Description | |
| url | url | Unique Identifier | |
| sameas | url | ||
| version | Text, number | in next version | |
| keywords | text | keywords | |
| variableMeasured | |||
| creator.name | Creator name (or publisher) | ||
| Catalogue | includedInDataCatalog | datacatalog | |
| Download | distribution | DataDownload | Handled within the UKRDDS client (CKAN) |
| distribution.fileFormat | text | ||
| distribution.contentURL | url | ||
| Temporal | temporalCoverage | ISO8601 | in next version |
| Spatial | spatialCoverage | GeoShape | Geolocation |
| Citation | citation | text | combination |
| Provenance | license | url, text | licence |
* version 3.1
** version 1.1
It is reassuring to see that there is a great deal of overlap between the profiles and are discipline neutral. As with the analysis done earlier this year, it is clear that there is a core set of metadata fields that almost all stakeholders believe to be central to discovery. What the involvement of a company as huge and ubiquitous as Google can do is provide a focal point for this work. It can also drive the use of standards, such as ISO8601. Experience on the Discovery service project suggests that date metadata can come in many different formats. Variance of this kind will severely impair the quality of search tools built upon the metadata. Having a powerful voice in the environment will help drive consistency.
Geospatial World graphic showing how Google science dataset schema works in the spatial and earth sciences domain.
Image sourced from https://www.geospatialworld.net/google-search-science-datasets-schema-geospatial/
The science dataset schema suggests a direction of travel for some of the topics posed by the New Paradigms group at the RDA 8th Plenary. Hopefully, the synergy here will lead to rapid progress in some areas the group agrees to explore. In its own right, Google’s schema may encourage a better quality and consistency of research data metadata, as global discovery incentivises researchers with the potential for greater citation and impact of their work.
Findable and Reusable
Google states that this dataset markup is available to experiment with before it’s released to general availability. Previews can be seen in their Structured Data Testing Tool but datasets do not appear in Search yet.
However, there will come a time when datasets do appear in Google search. This is desirable in SEO terms but the markup will also open the metadata to consumption through the tools that Google and other search engine giants produce, such as Knowledge Graph. Schema.org offers a much richer descriptive metadata set for a dataset (many of which can also be mapped onto the Discovery service profile) which may offer up the potential for a new set of tools to be constructed around research datasets. This extended set overlaps substantially with the creative work entity, which takes away the science focus of the simpler schema.
Alongside this, it is worth noting the work of Frictionless Data, who seek to provide standards for the containerisation of data for a specific tool required by a user according to standards developed for open source software. This additional structural markup gives the data immediate reuse value and creates it’s own searchable parameter. The coupling of simple, consistent metadata statements for discovery with fixed standards for data packaging provide a tantalising glimpse at truly FAIR data.
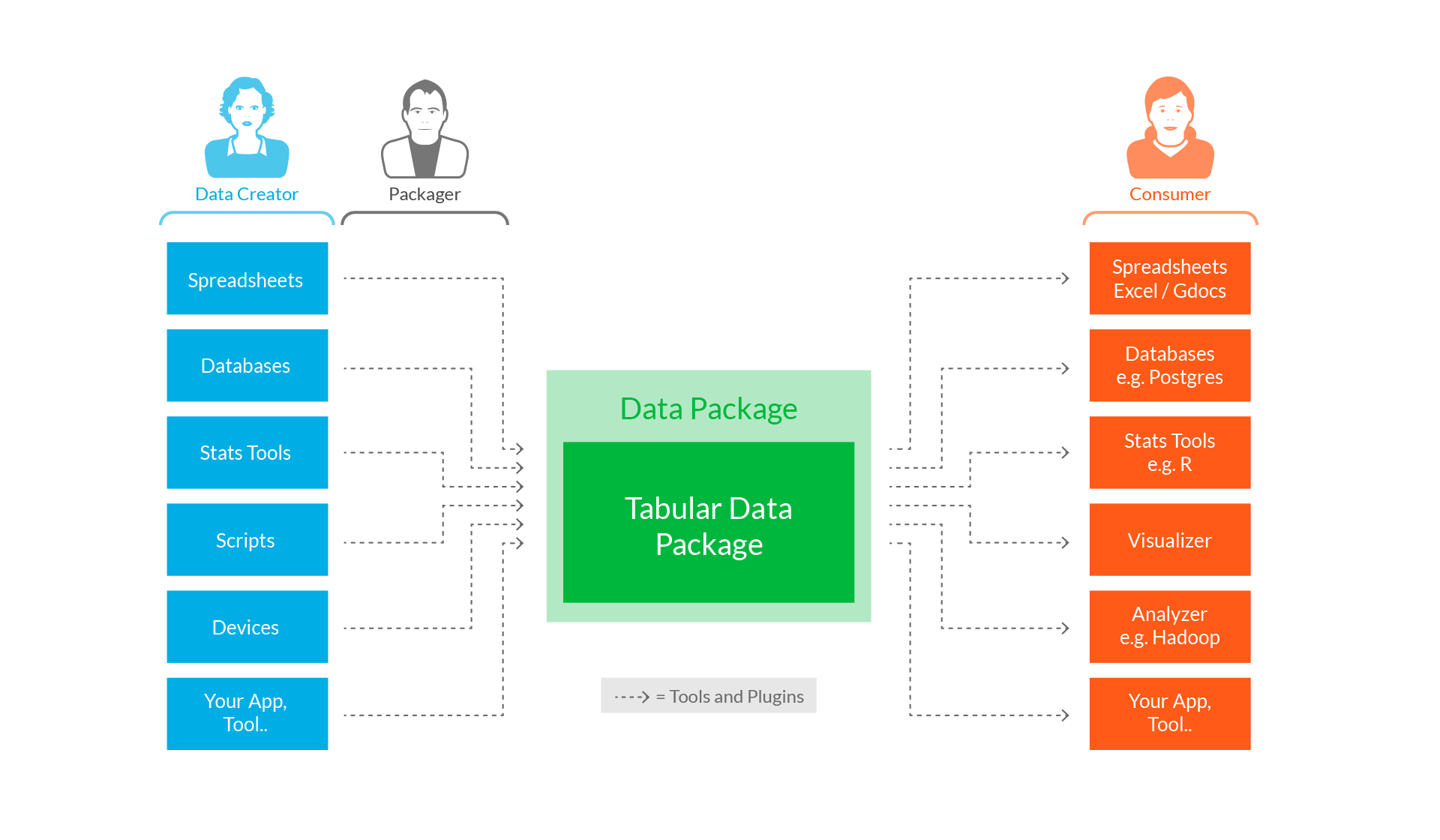
Schematic showing the Frictionless Data vision. Image sourced from: http://frictionlessdata.io/about/
It is worth noting that Frictionless Data focuses on tabular data.at the present time. There may be an element of technical simplicity in this decision but it also makes sense from a user perspective. Starting with a common data format makes sense to encourage wide adoption and the scope can be extended once a solid user base develops. It is probably the same reason for Google giving a tabular dataset example in its blog about the schema, although it seems that other data types are supported.
Simple is beautiful
To return to phase three of the UK Research Data Discovery service project, some significant avenues of exploration have opened up for metadata. There a sense from the pilots (as evidenced at the latest workshop) and from the international research data discovery community (as evidenced at the RDA 8th plenary) that discovery might concentrate on fewer, better structured and consistently populated metadata fields. This is not to subjugate all other available metadata but assert the roles that different metadata plays for different purposes such as access and reuse. First the data has to be found.
If this sounds like Dublin core all over again, it is worth noting that Google’s synonymy with discovery means that their dataset schema offers a template for what discovery and search metadata looks like to the global market.
Simple is an attractive prospect in the complex world of research metadata. As a result of Google’s entry into the space and the possible routes of travel discussed at the RDA New paradigms for discovery group, there are credible discussions on the horizon to build consensus about what discovery looks like, what it’s made up of and how it benefits the users and producers.