…Or how can RDSS bring more value?
The update and demo on the Jisc research data shared service (RDSS) last week attracted interest from more than 30 UK HEIs, a handful of overseas universities, plus many UK and overseas based associated organisations (including advocacy groups, funders and suppliers). If you didn’t manage to attend, the webinar was recorded, and the presentation is available on slideshare.
After the webinar, an attendee asked me what the actual benefit of installing the RDSS would be? In short, they asked ‘What’s the problem with researchers simply depositing straight to existing repositories?’.
It’s a good question, and the answer is probably ‘Nothing! But …’
RDSS manages an HEI’s entire data portfolio
From the researchers’, and to some extent the funders’ perspective, as long as the data is held in a repository ‘somewhere’, the basic requirement of making their data accessible has been fulfilled.
In addition to universities already managing their own repositories, there are numerous subject, funder and publisher repositories available. But, rather than focussing on the researcher or dataset, Jisc RDSS is responding to the increasing need of HEIs to oversee the management of all datasets produced by its academics.
Data management practices are lagging behind Open Access publications management but there are a number of similarities in the trajectory. As with Open Access, it’s clear that HEIs will be increasingly required (by mandate and good practice) to manage effectively all the datasets that their researchers are generating. Consider the comparison: a researcher can make a single publication open access by paying an APC or using a subject-based repository. But, to ensure compliance and good practice across the institution, HEIs rely on integrated systems (CRIS / local repositories) to facilitate effective management of their entire open access portfolio.
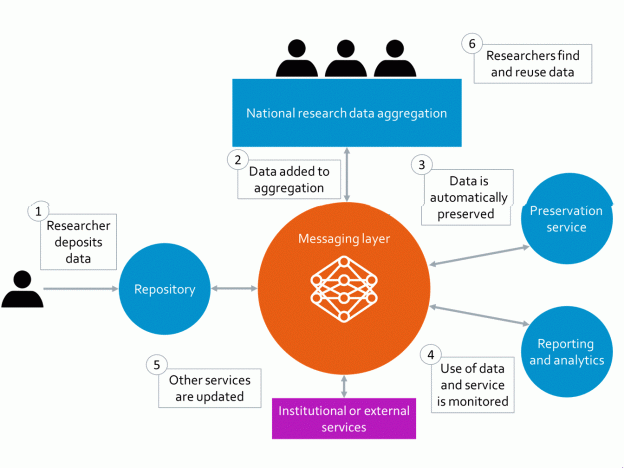
In a similar way, the RDSS can be used to record all deposited datasets, even those deposited on different platforms. All data generated by researchers from an individual HEI can be tracked, thus providing a canonical record for reporting, compliance and showcasing their research. The messaging layer that sits at the heart of RDSS also enables reporting functionality, the aggregation and discovery of datasets and the integration with other systems and services, including scholarly comms services such as ORCiD and DataCite (see Figure 1 below).
RDSS automatically ingests deposited data into the preservation system
Beyond this, the RDSS messaging layer facilitates the automatic ingest of deposited data into another component of the service, the preservation system. This eliminates the often manual step of digital preservation required to keep data readable and usable. A significant number of even large institutions have not yet properly tackled the issue of digital preservation, meaning the increasing number of funder mandates for the preservation of data in a usable format are not being met.
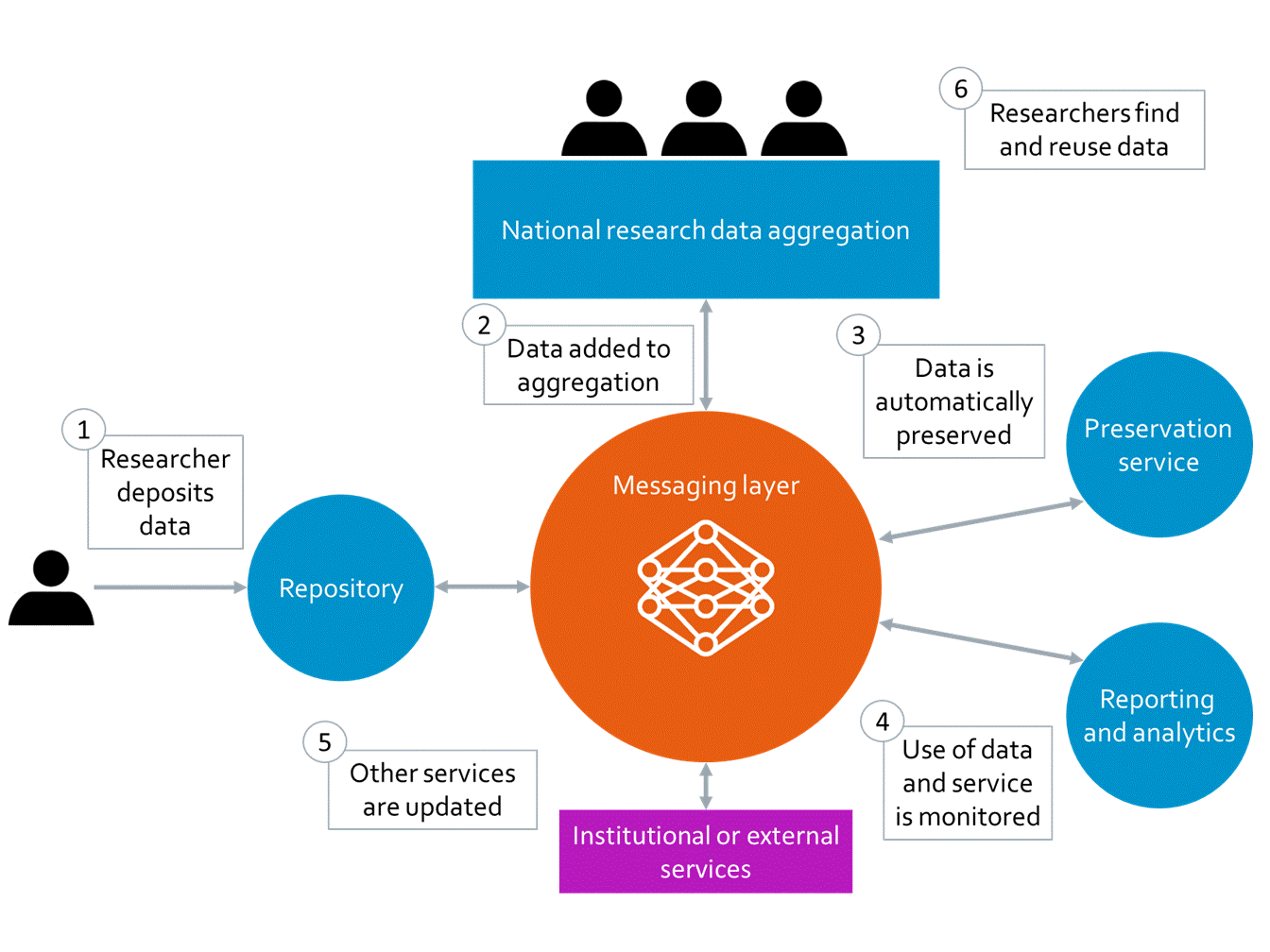
Figure 1: The main workflows facilitated by the RDSS messaging layer
Other features
There are also more basic practicalities for HEIs. Many smaller HEIs do not yet have fit for purpose data repositories or are looking to upgrade their publications repository to store data. Most institutions that we have engaged with are having to deal with additional issues such as managing large files, big data sets and sensitive data; areas which not all subject-based data repositories are able to tackle. The Jisc RDSS is being built with all these considerations in mind.
What’s in it for the researcher?
Looking back at the original question, it could also have been framed as, ‘So what is in it for the researcher?’
The RDSS provides a single place to store and share datasets, whether or not they are linked to publications and regardless of funder, publisher or subject area. Records of datasets stored elsewhere can be kept alongside, providing a single point of reference for the researcher. The RDSS also provides the freedom to publish datasets during the lifecycle of a research project, rather than at the end, which can be the case with a funder repository. This feature is very important for linking datasets to papers that are published during the project.
As mentioned above, the RDSS also provides a fully automated, intelligent preservation functionality that kicks in as soon as a dataset is deposited. This ensures that deposited data is preserved for the long-term without the burden of uploading files again to a different system.
Some researchers are lucky enough to have access to funder or subject data repositories, but there is a mid to long tail of researchers who don’t. Engagement with the RDSS project will provide benefits for both types of researchers and the HEI overall.