The Jisc Research Data Shared Service (RDSS) project team spent the first part of this year visiting different parts of the country (and world) to provide updates on the RDSS project.
It therefore seems timely to also provide an update on the project on our blog.
Looking back
At the end of Alpha development in January, the project underwent a root and branch ‘Stage Gate review’, covering both the technical and financial aspects of the project. The review considered whether it would be effective to run the service at scale. It also looked at how the project fitted into the forthcoming Jisc Research Strategy and the wider Open Science agenda.
A major obstacle identified during the review was that our choice of open-source repository, Samvera, did not provide a truly multi-tenanted solution. Instead, a separate cluster was necessary for each institution. Multiple single instances are expensive to host and maintain and are not scalable. This finding therefore had serious cost and sustainability implications for a multi-institution solution. In addition, there were difficulties in making changes to the code base (5 developers worked on this for 5 months – see footnote), it was difficult to change the look and feel of the repository and the user experience was not as good as we want to achieve.
Moving forward
During the technical review it was noted that the existing RDSS infrastructure (metadata store, messaging service, associated APIs and object storage) had all the features required of a multi-tenanted repository except the front-end interfaces. Given this, it was decided to build a proof of concept API to determine if a user interface could sit directly on top of this. This work confirmed that adding a lightweight front end to the existing infrastructure was feasible.
Introducing the Jisc Research Repository
The main requirements for the RDSS repository remain the same:
- a truly multi-tenant system (providing affordability, scalability and a single management view for different brands);
- able to handle multi content types;
- which will sit on the RDSS canonical data model for querying functionality and interoperability;
- and provides a good user experience.
With the successful proof of concept work described above, the team are now re-engineering the repository’s core infrastructure so it can easily interoperate with other tools and systems. The approach is utilising industry-based standards, such as building Javascript front ends. This means we can bring in new developers easily, if it is necessary.
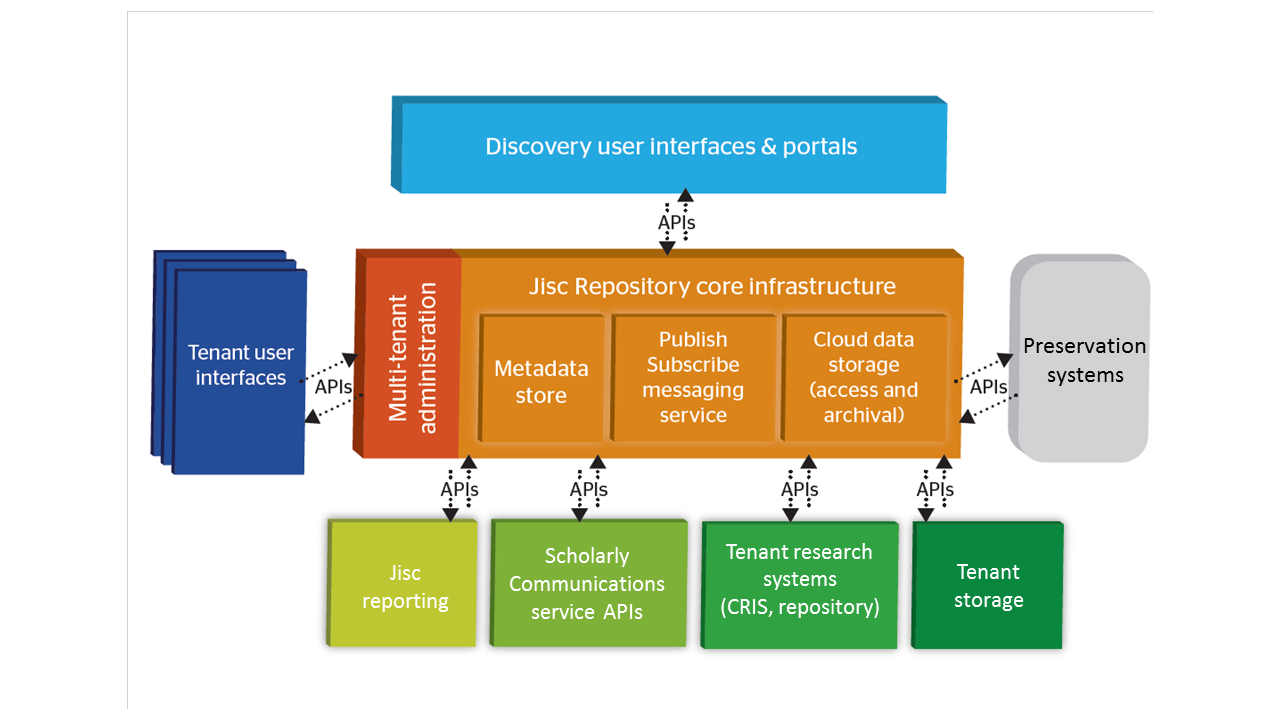
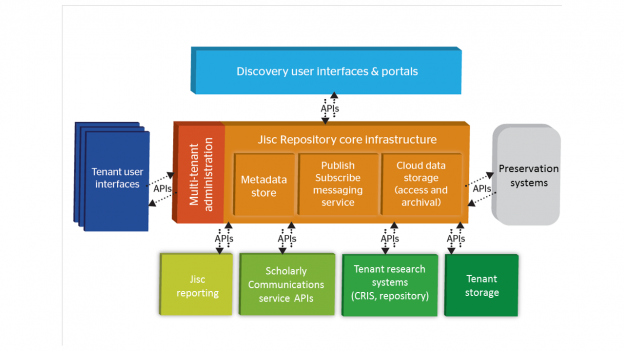
The core repository architecture will use APIs to link out to management and user interfaces, reporting functionality, preservation, storage, aggregators and other tools, systems and websites. This flexible approach will facilitate high levels of interoperability with other research management products (such as a CRIS), scholarly communications tools and even the institution’s current repository, if preferred. The institution’s preferred storage option can also be accommodated, as long as there is a persistent link.
This infrastructure provides the end to end research data management functionality desired by the sector, but with a ‘plug and play approach’ where institutions can integrate different systems into their solution at different points, depending on their needs and preferences.
Our Canonical Data Model and Message API Specification are openly available and can be used to create interoperability with other systems. We have already built adapters for Archivematica, Preservica, Figshare, Samvera and Eprints. We are currently working on a DSpace Adapter and looking at CRIS systems.
Where are we now?
The core repository infrastructure is built, providing the messaging system, multi-tenant database and interoperability layer. In addition, full integration with preservation systems was developed as part of the Alpha MVP, and so this is also already in place.
What are we currently working on?
With our design and UX partners, Ocasta, we have started the design work for our front end multi-tenant management and user interfaces. Some example wireframes are available and we will be releasing more soon.
In addition, we are working on:
- key workflows such as researcher deposit, administrative mediation and end user discovery and downloads;
- integrations with open access services and identifiers;
- institutionally branded interfaces (for example, for a main repository and any special collections);
- the reporting functionality (provided by DMAOline)
- development of APIs for other systems.
The future
Our priority is to deliver to the sector an effective end to end solution for research data management. This work is progressing well through Beta towards a transition to service date of November 2018.
However, we are also aiming to broaden out our perspective to address the wider open science agenda, with aim of including all research outputs (including publications and methods – provenance/code/metadata). Ultimately, the service should form part of the Jisc Open Research Offer and join up to other Jisc services. The vision is a shared service for open research with interoperability at the heart of service. We are also investigating opening up the service to digital objects beyond research to provide HEIs with a cost-effective solution to other digital archiving requirements.
Show me the money
We have been working on a financially sustainable business model. The model incorporates a number of assumptions, such as the number of Jisc staff required for service provision and continued development, plus other costs including licenses, compute costs and overheads. Our pricing approach places institutions into price bands based on research income and is broadly in line with the prices for other providers on the open market.
Storage costs in our model are based on average estimates. Currently we are using quite conservative estimates. This means that at present they are higher than we expect them to be at transition to service. The best market rate will be passed on to institutions, who can also use their own storage if preferred.
We are not seeking to make a profit, just to cover our costs. Any surplus will be invested into other Jisc services. Pricing will continue to be reviewed prior to the service being released.
As previously outlined, our offer to HEIs will be one of three options
- fully managed service (Jisc repository, preservation + reporting);
- preservation only (+ reporting);
- repository only (+ reporting)
In each case, HEIs will benefit from the central core infrastructure to facilitate integration with other systems. The key benefit is that Jisc handles the integration and management of different services, rather than each institution joining and up managing different services individually.
At present, if HEIs wish to choose other providers to plug in this infrastructure, institutions will negotiate with vendors directly. However, in the future, we are hoping to develop a procurement framework, which would require transparent pricing from any vendor signed up.
Next step
As we approach transition to service, we also plan to hold public webinars and demos. In the meantime, if you are interested in talking to us in more detail about any aspect of the service, please do not hesitate to get in touch.
Footnote
The review of Samvera functionality was presented at Open Repositories in July this year. We are writing a report for the Samvera community; we will link to this report when released.