Over the past two years, we have been developing a solution for researchers and support staff within universities to enable them to deposit and preserve research data for the long-term, while also monitoring and quality-checking the process. We set out with a critical requirement: the service must provide an oversight of all gaps where an institution is not complying with funder requirements and best practice around sharing and preserving data, so that administrators could focus on following up with the research groups that need help, rather than wasting their time on figuring out who those groups are.
Whilst the sharing, preservation and the general management of research data is not a new problem area, it has been growing in importance over the past years due to several reasons, both carrots and experimental sticks. The most common are: the issue with reproducibility, better research, more collaboration, funder requirements, H2020 data pilot. Several higher education institutions in the UK have thought about research data management and have given it some priority within their strategy. Most institutions implemented data policies, some tendered for solutions and as a result are running data repositories or combined data and publications repositories. Preservation is still a rare happening for research data. There are a variety of open and closed systems that support the deposit, or the preservation of data. We are working with a few of them to build the research data shared service.
Research data shared service: what does it do exactly?
The research data shared service provides a data repository function where researchers can deposit and share research data at an institutional level. In the background this data is automatically preserved after researcher deposit and after its metadata is verified and approved by an administrator. We are developing 3 major building blocks for the end to end offer: repository, preservation and analytics. Currently we are in the alpha stage of development and are going into beta in 2018 before launching the service. We are working with 16 UK universities and more than a dozen vendors that are either supplying their system (like figshare and Preservica), or supporting the development of the service and the open source platforms within the service (like Arkivum, Artefactual Systems, Digirati, Leidos, Ocasta etc).
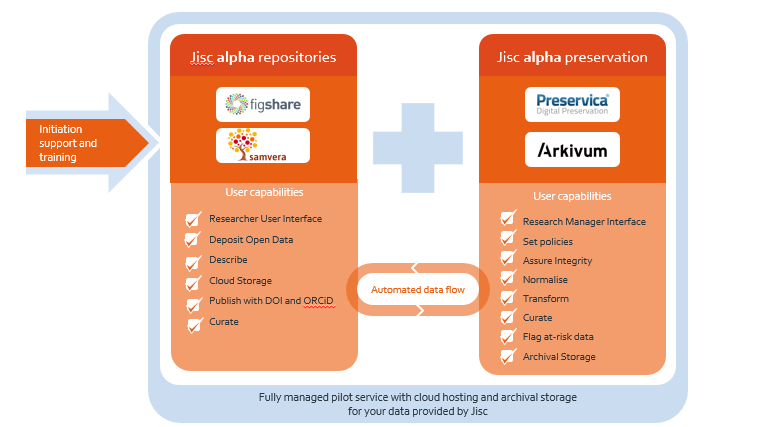
Alpha: deposit and preserve
In alpha, we are automating the flow of data between the repository and the preservation systems (and creating automated preservation ingest workflows). This removes the extra manual upload of data to the preservation system and starting a preservation workflow. The research data support and the preservation specialists within institutions would have the ability to check the quality of the data and metadata on both systems with administrator roles.
On the repository side, we are working with figshare and are also developing the open-source Samvera repository inhouse. On the preservation side, we are working with Arkivum and Artefactual Systems on archivematica, and Preservica.
Beta: adding analytics
In beta, we will focus on adding the reporting layer and developing a few more workflows and use cases for different types of data.
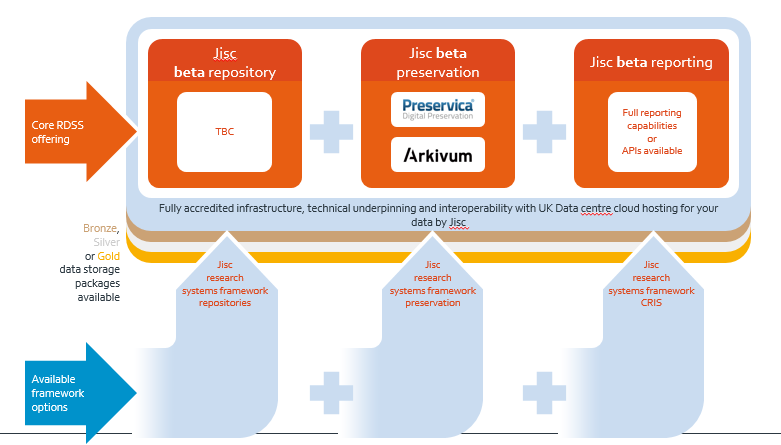
The business offer and operational models
We are also developing the offer and the operational model for the service. We tested the options and a draft series of proposed costs with the 16 pilot institutions and several non-pilot institutions via the market research work package.
The three options we are looking at right now are:
- An end-to-end service, which will include the repository, preservation and a full reporting layer, with all standard integrations between these systems and potentially other local systems the institution is using.
- A repository service, which will include basic reporting from the repository.
- A preservation service, which will include basic reporting from the preservation system. Currently, two pilot institutions within the project are testing the preservation-only option (University of St Andrews and University of Glasgow)
We are testing the options and the costs in an iterative way, and expect these may change depending on the responses we are collecting and the level of commitment to taking up the service. If you are interested in the shared service and would like to have a chat with us about your plans, any suggestions you already have or the challenges you are facing so we can understand better whether the service will help your institution, then do get in touch.
We are running a live demo of the Jisc alpha research data shared service on January 10, at 10 am. Please register for the webinar here.